偷2396部黄片训练AI老司机Meta被告惨了

偷2396部黄片训练AI?老司机Meta被告惨了!
当人工智能飞速发展撞上传统版权法,一场史无前例的大戏正在上演。最近Meta摊上大事了,被人告了说他们偷了2396部小黄片来训练AI,要赔3.59亿美元!这事儿不光是把AI训练的黑幕给扒了个底朝天,更是把整个科技圈推到了风口浪尖上。

一、Meta这回真的栽了个大跟头
美国加利福尼亚州法院最近受理的一起诉讼案件,将全球科技巨头Meta推到了舆论的风口浪尖。两家成人影片制作公司Strike3和Counterlife Media的联合起诉,不仅揭露了AI训练背后的数据获取黑幕,更以高达3.59亿美元的索赔金额,为整个科技行业敲响了版权保护的警钟。
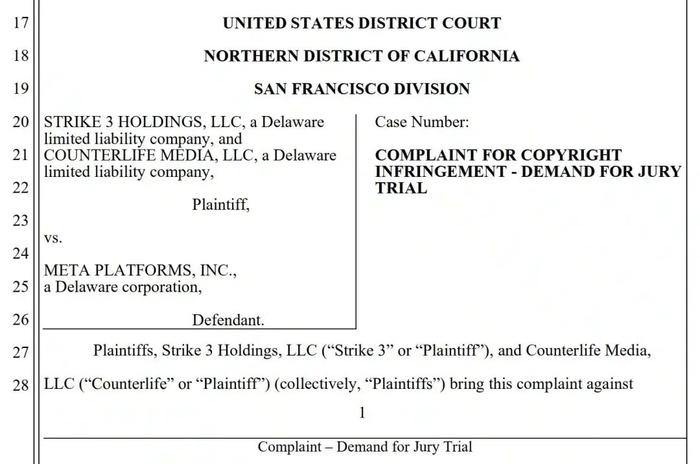
根据法庭文件显示,Meta公司自2018年以来一直在明知故犯地从盗版来源下载受版权保护的影片内容,累计涉及至少2396部作品。这些非法获取的视频资料被用于训练包括Meta Movie Gen视频生成模型和LLaMA语大模型在内的多种AI系统。
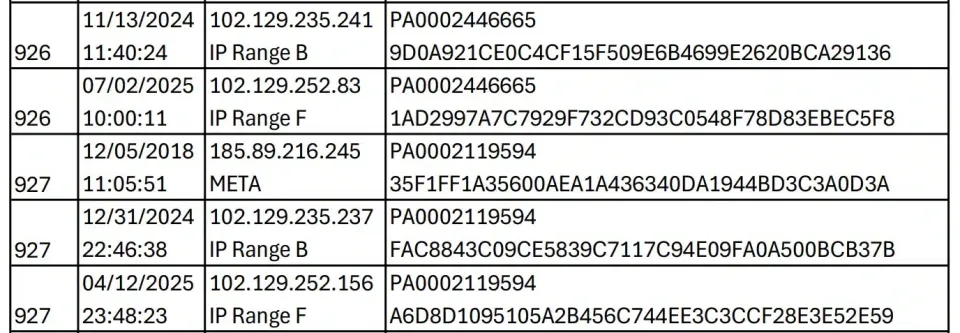
更让人跌破眼镜的是,Meta不是简单下载就完事儿了。根据起诉书,Meta还玩起了BT下载那一套,不光自己下,还做种子让别人下,就为了让自己下载速度更快。Strike 3公司用他们的追踪系统VXN Scan,查出了47个跟Meta有关的IP地址。这些IP多年来一直在疯狂下载他们的片子,而且一看就不是人干的——全天候、高频率、各种清晰度的片子同时下,这哪是正常人看片的节奏啊!
二、为啥小黄片成了AI训练的”香饽饽”
成人影片成为AI训练素材并非偶然。这类内容具备其他数据无法比拟的技术优势:画质高、镜头稳定、表情自然、动作连贯。对于视频生成模型来说,这类内容提供了罕见的”长时段自然人体画面”、“独特的人体交互与表情”,这些素材正好填补普通视频数据中缺失的部分。
说白了,训练视频AI需要大量有人物动作、表情变化的视频。小黄片正好全占了:时间长、互动多、表情丰富、角度多样。这些特点让它成了训练AI理解人类行为的”完美教材”。
Meta选择盗播这些视频,是为了加速下载其它更大规模的数据集。他们有选择地”挑片种子”,用最受欢迎的情色内容当做”下载货币”,换取快速获取其它数据集。说白了,Meta把这些热门小黄片当成了BT世界的”硬通货”,用来换取下载速度,这操作真是绝了。
三、AI训练到底算不算”合理使用”?这事儿吵翻天了
1. 法律是咋规定的
合理使用的原则是在使用他人作品时的一个法律概念,即允许在一定范围内使用他人的作品而无需获得授权,通常是为了教育、评论、新闻报道等非商业性目的而使用。在美国的《版权法》中,判断一个行为是否是合理使用需要同时考量以下四个要素:(1)使用的目的和性质;(2)受版权保护的作品的性质;(3)使用受版权保护的作品相关部分的数量和实质性;以及(4)使用受版权保护的作品对受版权保护的作品潜在市场的影响。
我国对著作权合理使用的基本规定分别在《著作权法》和《著作权法实施条例》。合理使用的判断需要符合著作权法列举合理使用具体场景和事由之一,同时满足实施条例所规定的三步检验标准(即作品已发表、不影响作品正常使用、没有不合理损害著作权人利益)。
简单说,你要用别人的东西,得看四个方面:你用来干啥、用的是啥、用了多少、对人家生意有啥影响。
2. AI公司说”我们是在学习”,法院说”你想得美”
Open AI始终秉持的观点是,认为与制作新闻、写作、作画等为了”人类娱乐”目的不同,训练生成式AI的目的是学习”人类生成媒体固有的模式”。OpenAI他们老说:“我们不是抄袭,我们是让AI学习人类创作的规律。”
但法院不买账啊!美国版权局驳斥了将AI训练类比人类学习的观点。合理使用原则并不自动适用于所有以学习为名的行为。人类对信息的吸收既不完美又具有个体差异性;而AI系统则截然不同,它们摄取精确的数字副本,并以”超人的速度和规模”处理它们。
说得明白点:人看书会忘,记得也不准;AI是一字不差全记住,还能瞬间处理几百万份。这能一样吗?
3. 最要命的是市场影响
法院强调市场影响是评估合理使用的最重要因素,需考量复制行为对原作品市场的影响,以及对AI训练数据这一潜在衍生市场的影响。
版权局明确指出生成式AI训练可能引发的三类市场损害:许可机会损失:针对本可通过授权许可将其作品纳入训练数据集而获得报酬的权利人;市场替代性损害:当模型生成的输出内容与训练数据集中的受版权保护作品构成实质性相似时;市场稀释:即使AI生成内容不构成直接侵权,但其通过海量产出或风格模仿导致原创训练材料的市场价值被削弱。
翻译成人话就是:第一,人家本来能收授权费的,你偷用了人家就赚不到钱了;第二,你的AI生成的东西跟原作太像了,抢人家生意;第三,就算不太像,你大量生产山寨货,也会让原作不值钱了。
四、不光Meta倒霉,科技巨头们都在挨告
Meta可不是唯一一个倒霉蛋,看看这些大公司都摊上啥事了:
2024年3月20日,法国竞争管理局宣布对谷歌处以2.5亿欧元罚款,理由是谷歌未能与出版商就内容使用和报酬达成协议,违反了2019年欧盟版权指令。谷歌被法国罚了2.5亿欧元,因为他们用新闻内容训练AI却不给钱。
2024年8月,作家安德莉亚·巴茨、查尔斯·格雷伯等人向法院提起集体诉讼,指控Anthropic存在”大规模版权侵权”行为,通过”影子图书馆”等盗版平台获取大量图书训练其AI模型Claude。最终,Anthropic于9月6日同意支付至少15亿美元达成和解,承诺按每部作品3000美元赔偿作者,并销毁所有涉嫌侵权的训练数据。Anthropic(就是做Claude的那家)更惨,赔了15亿美元!每本书赔3000美元,还得把偷来的数据全删了。
早在2023年6月,美国作家协会及多位畅销书作家,包括《冰与火之歌》作者乔治·R·R·马丁、作家莎拉·西尔弗曼和迈克尔·夏邦等发起集体诉讼,指控OpenAI大量使用他们的版权书籍训练模型,甚至生成原文摘要和续写。连《权力的游戏》的作者马丁老爷子都告OpenAI了,说他们偷书来训练ChatGPT。
五、法院最近都是咋判的
1. 美国法院:用了就是侵权,别找借口
2025年2月11日,美国特拉华州地区法院就汤森路透诉罗斯智能案作出判决。根据判决思路,在AI模型训练过程中,即使数据仅用于模型的训练,而非最终产品的直接展示,未经授权使用受著作权保护的数据仍然可能构成侵权。
这个判决特别重要,法院说了:就算你只是拿来训练,没直接展示给用户看,那也是侵权!别想钻空子。
2. 但德国法院说:搞科研可以用
2024年9月27日,德国汉堡地区法院就摄影师Robert Kneschke与非营利性协会LAION诉讼案作出裁决,法院认为被告LAION对原告摄影作品的使用行为符合《德国版权法》“科学研究目的”和”文本与数据挖掘”的侵权例外情形,因此驳回原告诉讼请求。
有意思的是,德国法院却说:如果是为了科研,那可以用。看来不同国家的想法还真不一样。
六、科技公司该咋办?别再偷偷摸摸了
现在科技公司得改改他们那套”先偷了再说,被抓到再道歉”的老路子了:
1. 老老实实买版权 :跟创作者谈好价钱,该给钱给钱,大家都有饭吃。
2. 搞点技术创新 :开发能识别版权内容的技术,训练的时候自动过滤掉没授权的东西。
3. 行业自己管自己 :大家坐下来定个规矩,啥能用啥不能用,说清楚。
4. 推动立法 :让法律跟上时代,既保护创作者,又不耽误AI发展。
基于AI的应用场景越来越广泛,从利益平衡方面,技术发展和公众利益需要全面充足的训练数据,故两者利益超越了版权人的利益,使用版权作品作为训练数据应当构成合理使用。虽然有专家这么说,但争议还是很大的。
七、写在最后:别让AI成了”强盗”
Meta这事儿只是冰山一角。这已经不是Meta第一次因数据盗版被告。2023年就有作家集体起诉Meta,指控其通过BT下载81.7TB盗版书籍训练LLaMA模型,当时Meta承认了BT使用行为。看来Meta是惯犯了,去年偷书,今年偷片。
说到底,AI再牛逼,也不能建立在偷东西的基础上。科技公司得明白:创新不是违法的挡箭牌,赚钱不能踩着别人的劳动成果。只有尊重知识产权,建立公平的补偿机制,AI产业才能长久发展。
未来肯定会有更多判例和新法律出来规范这事儿。但在那之前,科技公司应该自觉点,别老想着钻空子。追求技术进步的同时,也得讲道德守法律。只有这样,人工智能才能真正造福人类,而不是变成一个”数据强盗”。
毕竟,谁也不想看到AI变成一个只会偷东西的”高科技小偷”吧?
以上就是今天分享的内容啦,觉得我的文章有用,记得一键三连,点个 关注、分享、喜欢 。 我正在组建一个 AI 副业公益群,每天都会分享一些 Al 的最新流量玩法和案例拆解,下方扫码备注“ AI ”拉你入群。
