DS论文精读:LM长上下文新解法DeepSeekOCR用光学压缩实现10倍记忆

【DS论文精读】LM长上下文新解法!DeepSeek-OCR用“光学压缩”实现10倍记忆扩容
今天,我又挖到了一篇AI Agent领域的“宝藏”论文,迫不及不及要和大家分享!
我们都知道,AI Agent的“大脑”——LLM,有一个众所周知痛点: 上下文长度(Context Window) 。当对话历史、文档资料、任务步骤变得越来越长时,LLM的计算量会呈二次方级暴涨,token很快就不够用了。这极大地限制了Agent执行长期、复杂任务的能力。
如果我告诉你,有一种方法,可以不把长篇大论的 文本 喂给LLM,而是先把它们”拍张照”,再把这张 图片 喂给LLM呢?
这就是我们今天的主角——来自DeepSeek-AI的最新研究: DeepSeek-OCR 。它提出的“上下文光学压缩”(Contexts Optical Compression),可能为AI Agent的长记忆问题提供了一个全新的、脑洞大开的解决思路!
论文速览:DeepSeek-OCR是做什么的?
简单来说,DeepSeek-OCR是一个VLM(视觉语言模型),但它的研究视角非常独特: 它不只是把OCR(光学字符识别)当成一个工具,而是把它当成一个“文本解压缩”的过程 。
2.1 核心思想:“光学压缩”
这篇论文的洞察点在于: ** 一个包含大量文本的图像,其占用的“Vision Tokens”(视觉令牌)要远远少于其等效的“Text Tokens”(文本令牌) ** 。
举个例子:一篇1000个单词的文档,如果转成文本token,可能需要1000多个token。但如果把它渲染成一张图片,模型可能只需要100个vision token就能“看完”这张图。
这就是”光学压缩”:利用视觉2D映射作为文本信息的高效压缩媒介。
2.2 核心贡献:惊人的压缩率
DeepSeek-OCR要验证的就是,这种压缩到底靠不靠谱?模型能否从被“压缩”的图片中,高精度地“解压”出原始文本?
答案是:非常靠谱!
- • 高精度压缩: 实验显示,当压缩比小于10倍时(例如,用100个视觉token去解码近1000个文本token),模型能达到 97%的OCR解码精度 !
- • 极限压缩: 即使在高达20倍的压缩比下,OCR精度依然能保持在 约60% 。
- • SOTA性能: 在实战中,DeepSeek-OCR在OmniDocBench基准上, 仅用100个视觉token,就超越了使用256个token的GOT-OCR2.0 。并且 使用不到800个token,就击败了需要近7000个token的MinerU2.0 !
一句话总结:DeepSeek-OCR证明了,以极少的视觉token实现对海量文本的高效压缩和高保真解码,是完全可行的。
核心技术深度解析:Agent如何实现“光学记忆”?
DeepSeek-OCR作为一个VLM,采用了标准的Encoder-Decoder架构。但它的魔鬼细节,全在Encoder(编码器)里。
3.1 核心架构:DeepEncoder + MoE解码器
- • 解码器 (The “Brain”): 它使用了 DeepSeek3B-MoE 模型。为什么用MoE(混合专家)?因为它 兼顾了效率和能力 。它拥有3B(30亿)的总参数量,但在推理时只激活约570M(5.7亿)的参数。这让它拥有3B模型的强大表达力,同时享受着500M级别模型的推理速度,非常适合OCR这种专业领域的任务。
- • 编码器 (The “Magic Eye”): 这就是本文的核心创新—— DeepEncoder 。
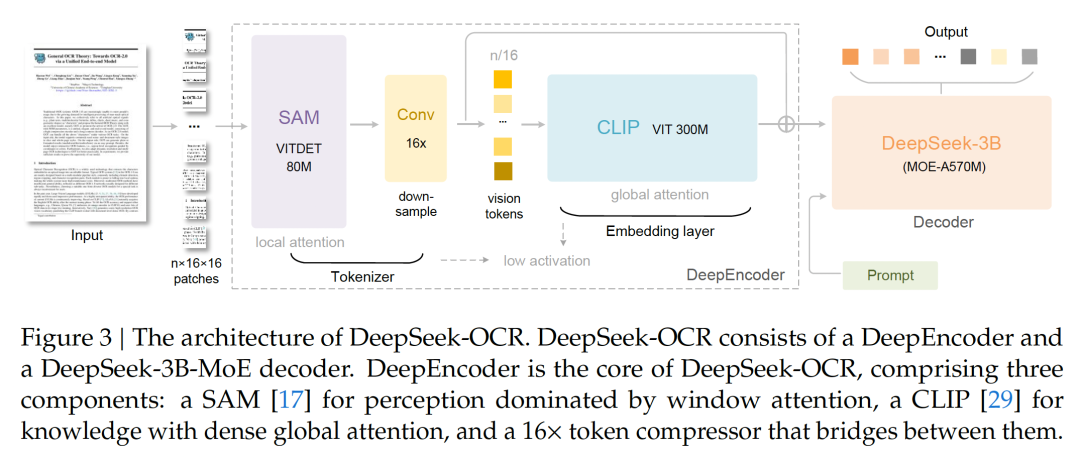
传统的Vision Encoder(如ViT)在处理高分辨率图片(这对看清密密麻麻的文字至关重要)时,会产生海量的vision token,导致激活内存爆炸。
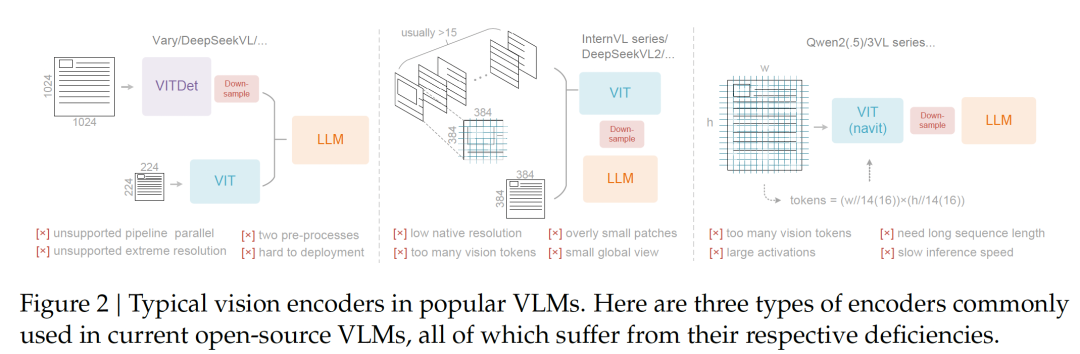
DeepEncoder的设计堪称精妙,它通过一个“串联”结构解决了这个问题:
- 1. SAM-base (局部感知): 首先,图片输入到一个80M参数的SAM(Segment Anything Model)。它主要由窗口注意力(Window Attention)构成。它负责处理高分辨率输入的繁重任务,因为局部注意力机制在内存控制上更友好。
- 2. 16x 卷积压缩器 (中枢压缩): SAM输出的大量token,会立刻进入一个2层的卷积模块。这个模块会执行 16倍的token下采样 。比如,SAM输出的4096个token,经过它之后只剩下 256个 。
- 3. CLIP-large (全局理解): 最后,这256个被高度压缩的token,才被送入一个300M参数的CLIP模型。CLIP采用的是 全局注意力(Global Attention) 。由于输入的token数量已经极低(只有256个),此时即使用计算昂贵的全局注意力,也毫无压力。
这个 “局部处理 → 强力压缩 → 全局理解” 的三级流水线,使得DeepEncoder既能“看清”高分辨率图像,又能保持极低的激活内存和极少的输出token。
3.2 关键机制:多分辨率支持
为了系统性地研究不同压缩比的效果,DeepEncoder被设计为支持多种分辨率模式,并且是 一个模型同时支持所有模式 ,这是通过动态插值位置编码实现的。
根据论文和GitHub仓库,主要模式包括:
- • Tiny: 512x512 分辨率 (Resize),输出 64 个视觉token
- • Small: 640x640 分辨率 (Resize),输出 100 个视觉token
- • Base: 1024x1024 分辨率 (Padding),输出 256 个视觉token
- • Large: 1280x1280 分辨率 (Padding),输出 400 个视觉token
- • Gundam: 动态分辨率(Tiling + Padding),例如 个token
这些模式让研究者可以像调节“压缩档位”一样,自由控制输入的精细度和token开销。
实验验证:效果究竟如何?
4.1 压缩比研究:10倍压缩,97%精度!
研究者在Fox基准上,专门测试了模型的“压缩-解压”能力。他们选取了包含600-1300个文本token的文档,分别用Tiny (64 tokens) 和 Small (100 tokens) 模式去“读取”。
结果如Figure 1(a)和Table 2所示:
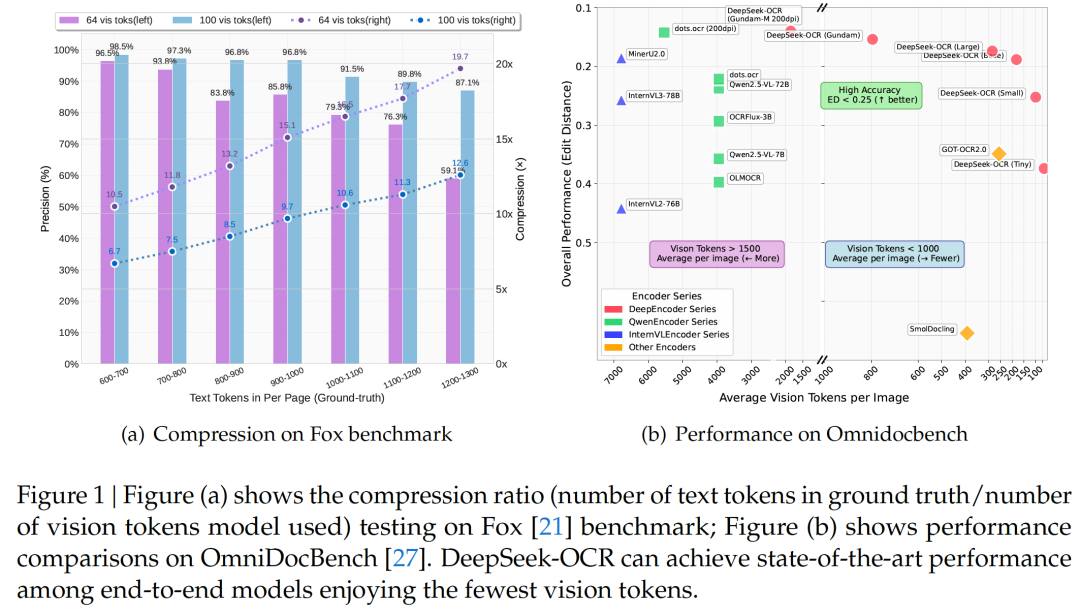
- • < 10x 压缩区 (高保真): 当文本token数在600-700时,使用100个视觉token(压缩比约7x),精度高达 98.5% 。使用64个视觉token(压缩比约10.5x),精度也高达 96.5% 。这几乎是“无损压缩”!
- • 10x-12x 压缩区 (性能下降): 当文本token数在1000-1100时,使用100个视觉token(压缩比约10.6x),精度下降到 91.5% 。
- • ~20x 压缩区 (极限压缩): 当文本token数在1200-1300时,使用64个视觉token(压缩比约19.7x),精度掉到 59.1% 。这说明信息开始“模糊”了,但也证明了模型在极限压缩下仍能抢救回大部分内容。
4.2 实用性研究:SOTA性能,最少Token!
在OmniDocBench基准上,DeepSeek-OCR展示了其作为OCR工具的强悍实力 (Figure 1(b)):
- • 以少胜多: DeepSeek-OCR (Small, 100 tokens) 战胜了 GOT-OCR2.0 (256 tokens)。
- • 降维打击: DeepSeek-OCR (Gundam, < 800 tokens) 显著优于需要6000+ tokens 的 MinerU2.0。
- • 全能解析: 它不仅能识别文字,还能进行“深度解析”,如解析图表、化学分子式、几何图形等 (见论文Fig 7-10)。
智使解读:这不仅是OCR,这是Agent“记忆”的新范式
读完这篇论文,我最大的感受是, ** 这绝不只是一篇SOTA的OCR论文,它更是一篇为LLM长上下文问题“投石问路”的概念验证(proof-of- concept) 。 5.1 论文亮点与贡献 1. 1. “光学压缩”概念: 这是最大的亮点。它将OCR任务从“识别”重新定义为“解压”,这个视角的转变打开了全新的想象空间。 2. 2. DeepEncoder架构: “SAM (局部) → Conv (压缩) → CLIP (全局)” 的架构设计非常优雅,它在不牺牲高分辨率的前提下,极致地压缩了token数量,是实现光学压缩的核心硬件。 3. 3. 惊人的效率: 实验数据(尤其是对比MinerU2.0) 证明了这种架构在效率上的绝对优势。
5.2 潜在应用场景:Agent的“遗忘曲线”
这篇论文对AI Agent的意义,远大于OCR本身。
- 1. Agent的长时记忆库: 想象一下,Agent的对话历史、执行过的任务记录、读过的文档……这些海量文本都可以被“拍照”渲染成图片,作为Agent的“光学记忆”存储起来。当Agent需要“回忆”时,它调用的不再是数万的text token,而是几百个vision token。
- 2. 模拟“遗忘机制”: 这是我个人认为最震撼的启发点!论文在Figure 13中完美地展示了这个思路:
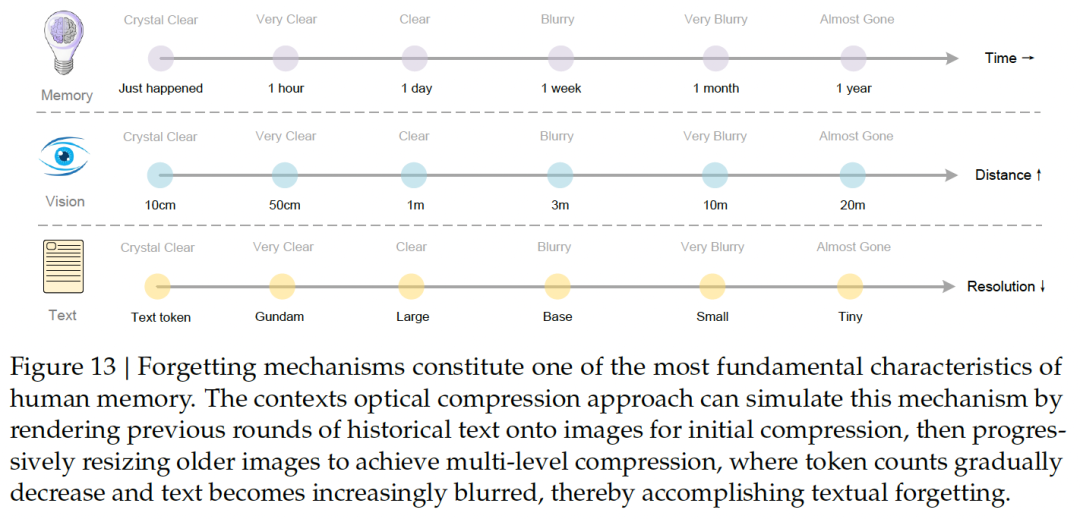
这不就是模拟了人类记忆的“遗忘曲线”吗? 越近的记忆越清晰,越远的记忆越模糊,但依然保留了核心信息(60%的精度)。这种机制不仅极大地节省了上下文空间,还让Agent变得更像“人”。
* • <strong>刚刚发生的 (Recent):</strong> 保持为高保真的 "Text token"。
* • <strong>昨天的 (1 day):</strong> 渲染成 "Large" 模式图片 (清晰)。
* • <strong>上周的 (1 week):</strong> 渲染成 "Base" 模式图片 (开始模糊)。
* • <strong>上个月的 (1 month):</strong> 渲染成 "Small" 或 "Tiny" 模式 (非常模糊)。
* 5. 3. 超级数据工厂: 论文提到,单卡A100-40G每天可以处理20万+页面的数据(或20个节点每天3300万页)。这使其成为一个强大的LLM/VLM预训练数据生产工具。
5.3 局限性与未来研究
作者非常坦诚地指出,这只是一个初步的探索。
- • 局限: 目前只是验证了OCR(文本解压)的可行性,但这不等于“真正的上下文理解”。
- • 未来: 下一步,他们将进行“数字-光学文本交错预训练”,并进行“大海捞针”(Needle-in-a-Haystack)测试,以验证LLM是否能像理解数字文本一样,真正理解这些被“压缩”的光学文本。
总而言之,DeepSeek-OCR 不仅是一个性能炸裂的OCR工具,它更是一个极具启发性的“思想实验”。它所展示的“上下文光学压缩”路径,特别是模拟“遗忘机制”的潜力,为构建更高效、更仿生、拥有超长记忆的AI Agent打开了一扇全新的大门。后台回复”OCR”获取论文PDF和代码
读完这篇硬核解读,你对“光学压缩”这个思路怎么看?你觉得它会成为未来Agent长记忆的主流方案吗?
欢迎在评论区留下你的思考!
以上就是今天分享的全部内容。如果觉得有所收获,记得一键三连,点个 关注、分享、喜欢 , 也 欢迎将文章分享给更多有需要的同学 。
我创建了一个高质量的 「论文研读社群」,专注于大模型、AI Agent等方向。在这里,我们 每日打卡 (精读并分享最新的Agent动态和顶会论文), 定期讨论 (围绕关键技术与研究思路进行深入交流), 资源共享 (共享高质量的学习资料与科研工具)。后台私信或下方扫码” Agent ”拉你入群。
