DeepSeek又出王炸不止是最强开源OCR

DeepSeek又出王炸:不止是最强开源OCR…
(。・∀・)ノ゙嗨,大家好!
今天,我给大家介绍一款刚开源就爆火的神器—— DeepSeek-OCR !
你是不是也受够了?从PDF里复制文字,格式全乱;想提取截图里的表格,只能一个一个手打;看到扫描版的文档,更是头皮发麻。
别慌!你遇到的这些抓狂瞬间,DeepSeek-OCR 都能摆平。它不仅是个简单的OCR(文字识别)工具,更是一个能“看懂”文档的AI。

它能把乱七八糟的文档、图片,瞬间转换成整整齐齐的Markdown,甚至连里面的图表、公式都能给你扒得明明白白!
今天这篇,就是零门槛的保姆级教程,带你快速上手这个大杀器!
本文目录
- 1. DeepSeek-OCR是啥? (它和普通OCR有啥不一样?)
- 2. 它到底能干嘛? (功能多到吓人!)
- 3. 零门槛!三分钟上手教程 (手把手教你跑起来)
- 4. 总结 (赶紧去试试!)
1. DeepSeek-OCR是啥?
简单说,DeepSeek-OCR 是 DeepSeek-AI 团队搞出来的一个智能文档解析模型。
它和咱们以前用的那些“截图识字”工具有本质区别。
- • 传统OCR: 像个“睁眼瞎”,它只认识字,不理解排版。你给它一个两栏的论文,它会一行一行“横着读”,结果就是一团糟。
- • DeepSeek-OCR: 像个“真学霸”,它利用了“上下文光学压缩” (Contexts Optical Compression) 的黑科技。它会先把整个文档当成一张“图” ,用视觉能力去理解它的结构、排版、哪里是标题、哪里是图表。
它最牛的地方在于 效率 。
其他AI大模型(VLM)也能“看懂”文档,但代价巨大。一篇文档可能要吃掉几千个“视觉令牌”(vision tokens),又贵又慢 。
而 DeepSeek-OCR 走的是“压缩”路线 。它用一个叫 DeepEncoder 的编码器 ,把高分辨率的图片信息“压缩”成极少数的视觉令牌 。
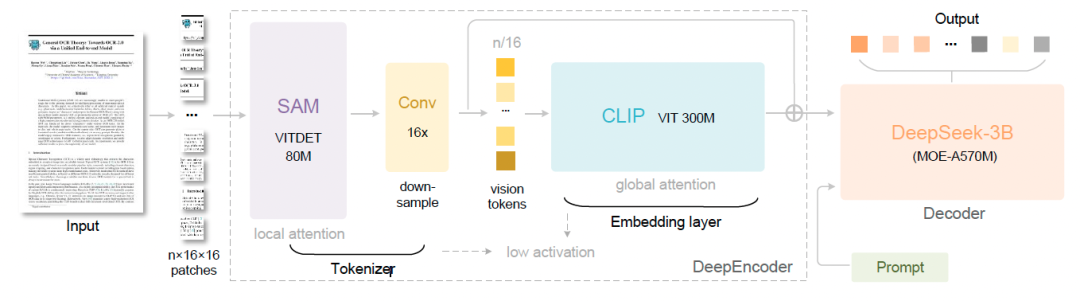
打个比方:别家模型看一篇文档平均要用 6000+ 个令牌 , 而 DeepSeek-OCR 用不到 800 个令牌就能搞定,效果甚至更好 !当压缩比在10倍以内时,它的解码(OCR)精度高达97% 。
省钱,高效,还聪明,这就是它火爆的原因。
2. 它到底能干嘛?
功能简直全能!
1. 复杂排版,一键转Markdown
这是它的基本功。无论是多栏的论文、带图表的报告,还是网页截图,它都能“看懂”排版,然后转换成格式完美的Markdown。
2. “深度解析”,图表公式通吃
这才是它的“杀手锏”。它不光认识文字,还认识文档里的“图”。
- • 解析图表 (Chart): 看到柱状图、折线图?它能直接把图里的数据提出来,转成 HTML 表格 。
- • 解析化学公式 (Chemical Formula): 看到复杂的分子结构图,它能直接转成 SMILES 文本格式 ,科研党狂喜。
- • 解析几何图形 (Geometry): 甚至连平面几何图形它也能识别 。
3. 近100种语言,随便识别
它在训练时学习了包含近100种语言的PDF数据 。所以不管你扔给它的是中文、英文,还是阿拉伯文、僧伽罗文……它都能搞定 。
4. 通用视觉能力
虽然它叫OCR,但它本质是个VLM(视觉语言模型)。所以你让它“描述一下这张图” 或者“图里的教师在哪里” ,它也照样能做。
3. 零门槛!三分钟上手教程
“别废话,怎么用?”
来了!官方提供了 vLLM(高性能)和 Transformers(标准易用)两种方式。作为零门槛教程,我们 ** 首选最简单通用的 Transformers 方式 ** 。
(需要你本地有Python环境和一块GPU)
第一步:下载代码和环境
-
1. 先把项目克隆(下载)到你电脑上:
-
2. 进入项目目录,并创建一个干净的Python环境(用Conda为例):
cd DeepSeek-OCR
conda create -n deepseek-ocr python=3.10 -y
conda activate deepseek-ocr -
3. 安装所有需要的“魔法包”(依赖库):
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 —index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
pip install flash-attn==2.5.8 —no-build-isolation
第二步:准备好你的“咒语” (Prompts)
DeepSeek-OCR 非常智能,你希望它干什么,就通过“提示词”(Prompt)告诉它。
这里是几个最常用的“咒语”:
-
• 转Markdown(最推荐):
prompt = "<image>\n<|grounding|>Convert the document to markdown. " -
• 只要纯文本(不要排版):
prompt = "<image>\nFree OCR. " -
• 解析图表/公式:
prompt = "<image>\nParse the figure. " -
• 常规看图说话:
prompt = "<image>\nDescribe this image in detail. "
第三步:开跑!
官方提供了一个 run_dpsk_ocr.py 脚本,但我们直接用Python代码跑更直观。
新建一个 test.py 文件,把下面的代码复制进去:
from transformers import AutoModel, AutoTokenizer
import torch
import os
# 指定用哪块卡os.environ["CUDA_VISIBLE_DEVICES"] = '0'
# 模型下载地址model_name = 'deepseek-ai/DeepSeek-OCR'tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 加载模型,注意这里用了 flash_attention_2 加速,显卡不支持就去掉model = AutoModel.from_pretrained( model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)model = model.eval().cuda().to(torch.bfloat16)
# --- 你的配置 ---
# 1. 选个“咒语” (从上面选一个)prompt = "<image>\n<|grounding|>Convert the document to markdown. "
# 2. 你的图片路径 (换成你自己的)image_file = 'your_image.jpg'
# image_file = 'your_document_page_1.png'
# 3. 结果保存路径output_path = 'your/output/dir'
# --- 开始推理 ---
print("开始处理图片...")res = model.infer( tokenizer, prompt=prompt, image_file=image_file, output_path=output_path, base_size=1024, # 基础分辨率 image_size=640, # 处理时的大小 (Small模式) crop_mode=True, # 自动裁剪 save_results=True, # 保存结果 test_compress=True # 测试压缩)
print("处理完成!结果已保存。") 把 image_file 换成你自己的图片路径,然后运行这个 test.py 文件。
稍等片刻,它就会在 output_path 路径下生成结果文件!一个完美的Markdown文档就诞生了!
4. 总结
DeepSeek-OCR 的出现,不仅仅是又多了一个OCR工具,它真正展示了“上下文光学压缩”这个新思路的潜力 。
它证明了AI可以不用堆砌海量的“令牌”,而是通过更智能的“压缩”方式来理解世界 。这种“先压缩再解压”的模式,未来甚至可能用来处理超长的对话历史 ,模拟人类的“记忆遗忘曲线” 。
总而言之,它 开源 、 免费 、 高效 ,而且 效果惊人 。
这绝对是近期最值得一试的AI项目!
大家赶紧去GitHub上给它点个 Star 体验吧!
觉得这篇文章有用? 记得帮忙点个“在看”和转发~ 感谢!
以上就是今天分享的内容啦,觉得我的文章有用,记得一键三连,点个 关注、分享、喜欢 。 我正在组建一个 AI 技术和副业公益群,每天都会分享一些 Al 的最新玩法和案例拆解,下方扫码备注“ AI ”拉你入群。
