OpenAI姚顺雨经典论文:Tree of Thoughts Deliberate Problem Solving

【OpenAI姚顺雨经典论文】Tree of Thoughts: DeliberateProblemSolvingwithLLM
我们都知道,现在的大型语言模型(LLM)很强,但它们在解决问题时,本质上还是一个“直肠子”——从左到右、一个Token一个Token地生成答案。这就像人类的“系统1”快思考,凭直觉、联想,速度快,但没法“深思熟虑”。
这种模式在遇到需要探索、策略规划、或者“走一步看三步”的复杂任务时,就特别容易翻车。比如,你让它玩24点,它可能第一步算错了,但它没有“回头路”,只能硬着头皮错下去,最后给出一个“无解”的答案。
为了解决这个“一本正经胡说八道”的难题,普林斯顿大学和谷歌DeepMind的研究者们联手,提出了一个全新的推理框架—— ** “思维树”(Tree of Thoughts, ToT) ** 。
这篇论文的核心,就是给LLM装上了一个“系统2”的慢思考模式,T让它不再是一条路走到黑,而是能像人类一样, 探索多种可能性、评估不同路径、甚至在发现走不通时“回溯”和“剪枝” 。
这篇论文就是:
《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》
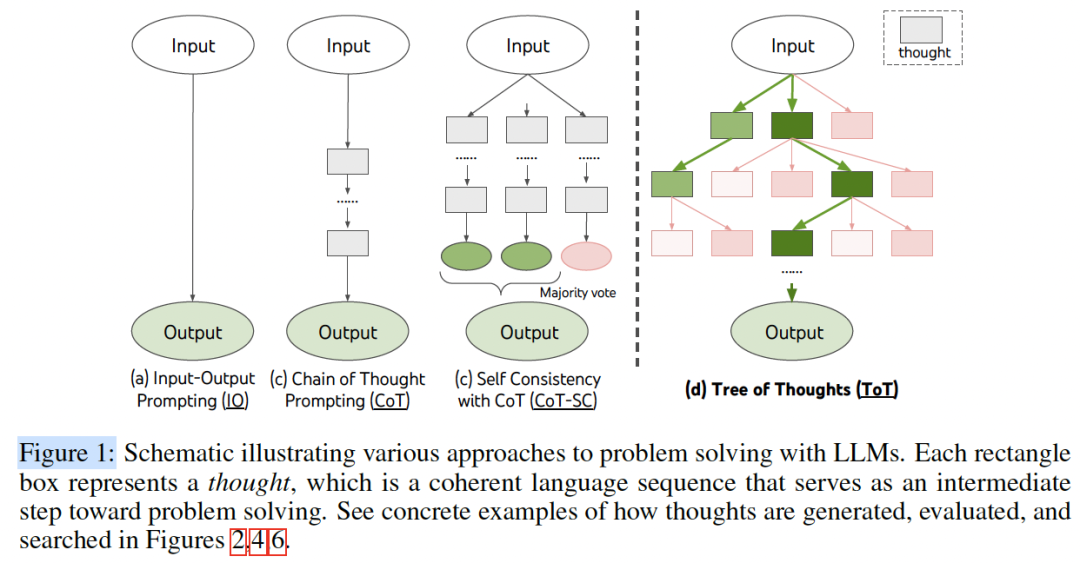
[ Figure 1 :ToT 与 CoT 等方法的对比示意图]
论文速览:ToT究竟是做什么的?
简单来说,ToT不是一个新模型,而是一种 全新的、用于LLM推理的框架 。
它把传统LLM的“思维链”(Chain of Thought, CoT)从一条“链条”扩展成了一棵“树”。
2.1 传统方法(CoT)的困境
- • CoT(思维链) :引导LLM一步一步思考,但本质上还是一条线性路径。
- • CoT-SC(自洽性) :多次运行CoT,然后投票选出最常见的答案。这只是探索了“多条”独立的链,但每条链内部还是无法回溯。
2.2 ToT的核心思想:探索+评估+回溯
ToT框架的灵感来源于人类的“系统2”思考和经典的人工智能搜索算法。它允许LLM以一种更系统化的方式解决问题:
- 1. 探索(Exploration) :面对一个问题,ToT不再只生成一个“下一步”,而是同时生成 多个 可能的“下一步”(即“思维”或“thoughts”),形成树的分支。
- 2. 评估(Deliberate Evaluation) :ToT会停下来,让LLM自己 评估 这些分支(中间步骤)的优劣。比如,“这条路看起来很有前途”或“这个中间结果离24差太远了,估计不行”。
- 3. 决策(Lookahead & Backtracking) :基于评估,ToT可以决定下一步的行动:是继续深入最有希望的分支( 前瞻 ),还是在发现此路不通时 回溯 到上一步,去探索其他分支。
核心技术深度解析:ToT框架如何实现“深思熟虑”?
作者提出,要实现ToT框架,你需要回答四个关键问题:
1. 如何分解问题(Thought Decomposition)?
你必须先把一个大问题,拆解成一步一步的“思维”单元。
- • 在“24点游戏”里,一个“思维”就是一步中间运算(比如
10 - 4 = 6)。 - • 在“创意写作”里,一个“思维”就是一段写作大纲。
2. 如何生成思维(Thought Generator)?
给定当前的“思维状态”(比如在24点游戏中还剩 4, 6, 9 ),如何产生下一步的多个可能性?
- • 独立采样(Sample) :让LLM独立生成k个下一步,适用于思维空间丰富的任务(如写作)。
- • 顺序提议(Propose) :让LLM在一个prompt里连续生成k个不同的下一步,适用于思维空间受限的任务(如24点)。
3. 如何评估状态(State Evaluator)?
这是ToT的精髓所在! ToT框架最大的创新之一,就是 利用LLM自己来充当“评估器”
,为搜索算法提供启发式(heuristic)信息。
- • 价值评估(Value) :让LLM直接给当前状态打分(比如1-10分),或者给出一个分类(比如
sure/likely/impossible)。例如,在24点游戏中,LLM可以判断10 13 13这三个大数“不可能”得到24。 - • 投票表决(Vote) :让LLM比较几个不同的分支,然后投票选出“最有希望”的一个。这在创意写作中非常有用,比如“Plan 2比Plan 1更连贯”。
4. 使用什么搜索算法(Search Algorithm)?
一旦有了生成和评估能力,你就可以套用经典的搜索算法来探索这棵树:
- • 广度优先搜索 (BFS) :在每一步都保留
b个最有希望的分支,同步推进。论文在“24点”和“创意写作”中使用了它。 - • 深度优先搜索 (DFS) :只沿着“最”有希望的那条路一路走到底。如果评估器说“此路不通”(比如分数低于某个阈值),就回溯(backtrack)到上一个节点,尝试第二有希望的路。论文在“填字游戏”中使用了它。
实验验证:效果究竟如何?
为了证明ToT的强大,研究者们专门设计了三个传统CoT方法难以解决的、需要规划和搜索的任务。
实验一:24点游戏(Game of 24)
- • 任务 :给定4个数字,用
+ - * /凑出24。 - • 传统方法 :GPT-4 + CoT的成功率只有 4.0% 。即便是CoT-SC(跑100次取最优),成功率也只有9.0%。
- • ToT(BFS, b=5) :ToT在每一步生成5个可能的算式,评估其可能性,保留最好的5个进入下一步。
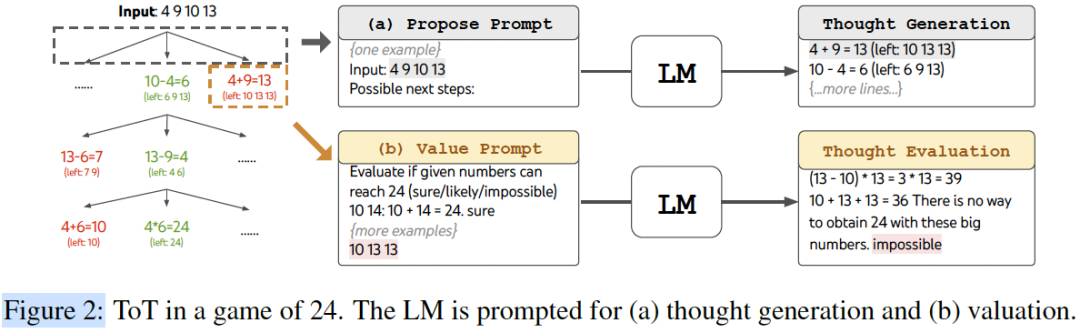
[ Figure 2 :Game of 24 的 ToT 流程(Propose 和 Value 示例)]
- • 结果 : ToT的成功率达到了惊人的74%!
[在此处插入 PDF 原文第 6 页的 Figure 3 :Game of 24 的实验结果图表((a) 成功率 vs 节点 (b) 失败步骤分析)]
为什么差距这么大?因为CoT经常在第一步就错了,然后一路错到底。而ToT会评估第一步的多个选项,及时剪掉那些“看起来就不可能”的路径。
实验二:创意写作(Creative Writing)
- • 任务 :给定4个随机的句子,要求写一个连贯的、包含4个段落的文章,且每段必须以给定的句子结尾。
- • 挑战 :这极度考验LLM的“全局规划”能力。
- • ToT :第一步,生成5个不同的“写作大纲(plan)”,然后LLM投票选出最好的大纲。第二步,基于这个大纲,生成5篇完整的文章,再投票选出最连贯的一篇。
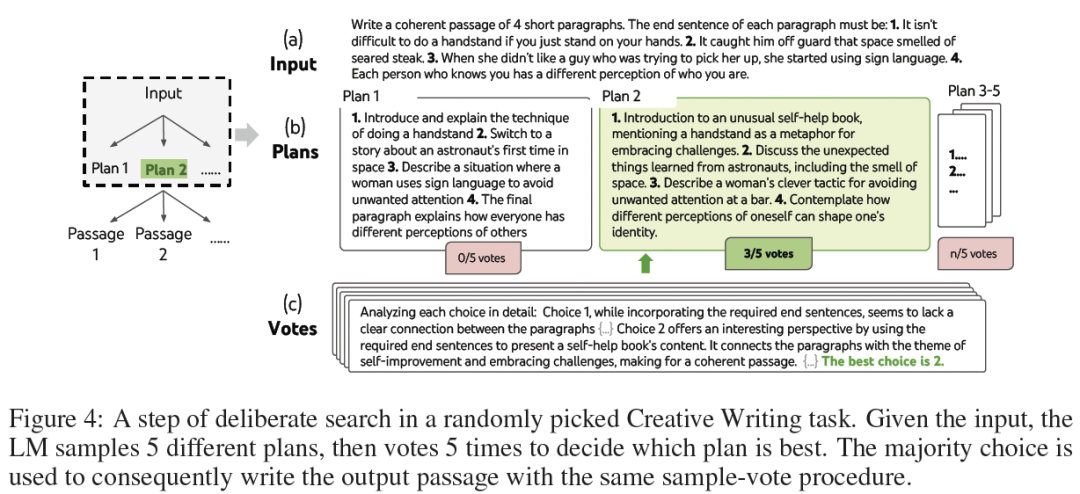
[ Figure 4 :创意写作的 ToT 流程(生成5个Plan并投票)]
- • 结果 :无论是GPT-4自动打分,还是人类盲评,ToT生成的文章在“连贯性”上都显著优于CoT。人类评审在41%的情况下更喜欢ToT的(CoT仅21%)。
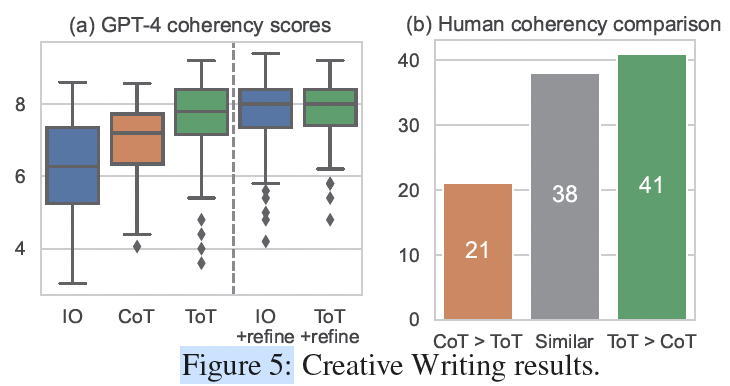
[ Figure 5 :创意写作的实验结果图表((a) GPT-4 连贯性得分 (b) 人类偏好对比)]
实验三:迷你填字游戏(Mini Crosswords)
- • 任务 :解决5x5的填字游戏,涉及复杂的约束和词汇推理。
- • ToT(DFS) :使用深度优先搜索。每次尝试填一个最有把握的词。如果填完后,发现某个剩余的空格(比如
tm_s_)变得“不可能”填上任何词了,系统就会触发“回溯”,撤销上一步,去尝试填别的词。 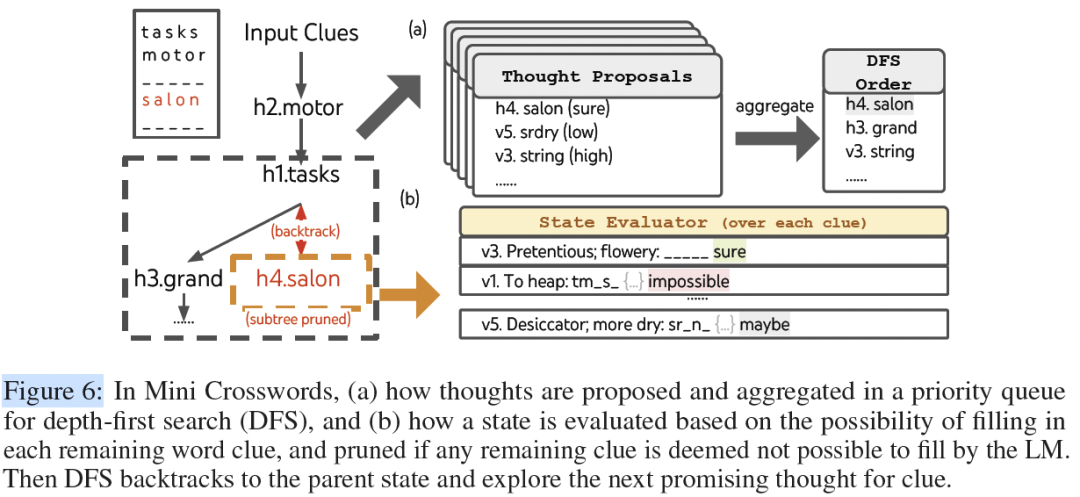
[ Figure 6 :迷你填字游戏的 ToT 流程(DFS、状态评估和剪枝)]
- • 结果 :CoT的单词级别准确率低于16%。而ToT的单词准确率达到了 60% ,并且成功解出了20个谜题中的4个(CoT一个也没解出)。
智使解读:洞察与展望
5.1 论文亮点与贡献
- 1. 从“系统1”到“系统2”的跨越 :这是ToT最大的贡献。它为LLM提供了一个从“直觉式”快思考转向“分析式”慢思考的框架,让LLM真正具备了“深思熟虑”的能力。
- 2. LLM即评估器(LLM as Evaluator) :这个思路非常巧妙。我们不需要额外训练一个复杂的奖励模型或评估器,LLM本身就具备强大的常识和推理能力,足以充当这个“启发式向导”。
- 3. 框架的通用性与灵活性 :ToT是一个高度模块化的框架。你可以根据不同的任务,自由组合思想分解方式、生成策略、评估方法和搜索算法(BFS, DFS,甚至未来可以接入MCTS蒙特卡洛树搜索)。
5.2 潜在应用场景
ToT框架的潜力远不止于此。任何需要复杂规划、探索和权衡的Agent任务都是它的用武之地:
- • 复杂代码生成与调试 :Agent可以探索多种API调用组合,评估其是否会导致bug,并回溯。
- • 机器人与具身智能 :在物理世界中规划一系列动作,如果遇到障碍,可以回溯并重新规划。
- • 科学发现与定理证明 :探索不同的假设路径,评估其合理性。
5.3 局限性与未来研究方向
当然,ToT也不是银弹。它最显著的缺点就是 计算成本 。相比CoT只跑一次,ToT需要进行大量的生成和评估调用,API成本可能会高出5-100倍。
不过,正如作者所言,这是为了追求更高性能所必须的开销。未来,随着模型本身推理能力的提升(更好的评估器)和开源模型的发展,这个成本问题有望得到缓解。
结论
总而言之,ToT是一篇具有开创性意义的论文。它不再满足于LLM“token接龙”式的回答,而是真正开始探索如何构建一个能够“思考”和“规划”的智能Agent。
这篇论文无疑为我们揭示了AI Agent未来发展的一个重要方向,它的思路值得我们反复品味。
大神们已经将论文和代码全部开源,复现跑起来!
- • Github :
https://github.com/princeton-nlp/tree-of-thought-llm
读完这篇硬核解读,你有什么新的启发吗?你认为“思维树”是通向更强AI Agent的必经之路吗?
以上就是今天分享的全部内容。如果觉得有所收获,记得一键三连,点个 关注、分享、喜欢 , 也 欢迎将文章分享给更多有需要的同学 。
我创建了一个高质量的 「论文研读社群」,专注于大模型、AI Agent等方向。在这里,我们 每日打卡 (精读并分享最新的Agent动态和顶会论文), 定期讨论 (围绕关键技术与研究思路进行深入交流), 资源共享 (共享高质量的学习资料与科研工具)。后台私信或下方扫码” Agent ”拉你入群。
