Agent智能体的未卜先知:当数字孪生遇上多智能体强化学习

Agent智能体的“未卜先知”:当数字孪生遇上多智能体强化学习
想象一下,在一个繁忙的边缘计算网络(比如智慧城市或自动驾驶的后台)中,一群AI“工人”(边缘节点)需要协同处理一堆复杂且相互依赖的任务。它们没有“总指挥”(去中心化),还得保证任务100%可靠,不能失败。
这就是个大难题!
- • 痛点1: 传统的“中央大脑”式调度,一旦“大脑”宕机,整个系统就瘫痪了,而且通信开销巨大。
- • 痛点2: 现有的“去中心化”方法,大多是各自为战的“莽夫”,它们往往忽略了任务之间的 依赖关系 (比如必须先A后B),也无视了 网络带宽 的限制(只管分工,不管路堵不堵)。这导致资源利用率低下,系统可靠性极差。
那么,如何让一群“各自为战”的Agent,既能高效协作,又能保证万无一失呢?这篇论文给出了一个极其巧妙的答案。
这篇论文发表在CCF A,中科院一区顶刊 IEEE Transactions on Mobile Computing (TMC) 上,标题是:协作边缘计算中的去中心化任务卸载:一种数字孪生辅助的多智能体强化学习方法
《Decentralized Task Offloading in Collaborative Edge Computing: A Digital Twin assisted Multi-agent Reinforcement Learning Approach》
链接🔗:
论文速览:概览与核心贡献
1. 这篇论文是做什么的?
这篇论文正面硬刚了边缘计算中的一个核心难题:“可靠性感知下的依赖任务卸载”问题。
- • 可靠性感知: 必须考虑节点可能失败。
- • 依赖任务: 必须处理有前后顺序的任务(如视频分析流程)。
- • 去中心化卸载: 没有中央协调者,每个节点(Agent)自己决定任务是本地执行,还是“甩锅”给别人。
目标: 在满足上述所有苛刻条件的同时, 最大化整个系统的“任务成功率” 。
为了解决这个问题,作者首先构建了整个系统的模型。
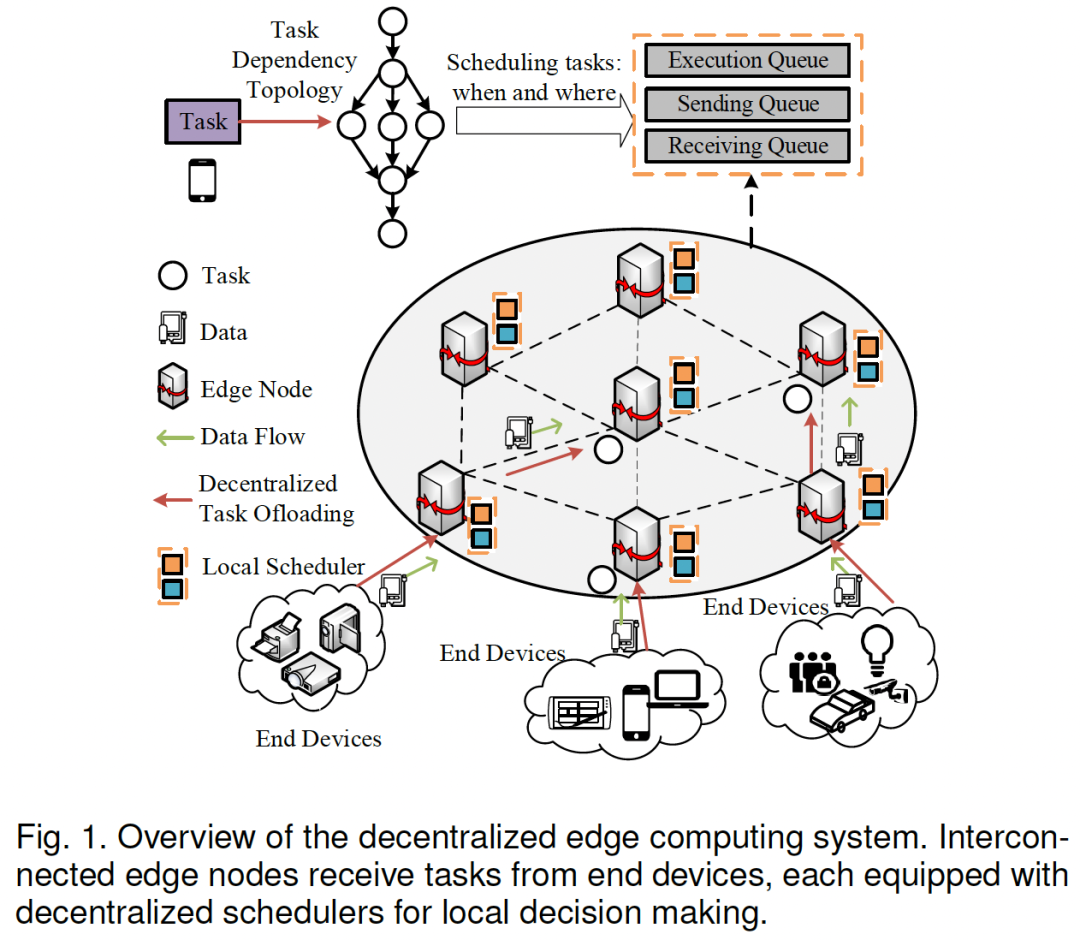
2. 核心思想/方法论:DT-MARL
论文的“杀手锏”是提出了一种名为 DT-MARL 的新框架。这可不是简单的“A+B”,而是让 多智能体强化学习(MARL) 和 数字孪生(Digital Twin) “灵魂合体”。
简单来说,每个边缘节点都是一个MARL智能体(Agent),它们自己做决策。但为了不让它们“瞎做”,研究者给每个Agent都配了一个“随身模拟器”—— 数字孪生(DT) 。
这个DT有三大“超能力”:
-
1. 降低探索风险: Agent可以在DT这个“虚拟世界”里大胆试错,而不会搞崩真实的物理系统。这对于自动驾驶、医疗等高危场景至关重要。
-
2. 提高样本效率: DT可以“脑补”出大量的未来数据,帮助Agent更快地学习和收敛,解决MARL的“训练慢”顽疾。
-
3. 实现主动决策: 这是最关键的一点!DT能实时预测“如果我这么做,未来会发生什么?”(比如任务要花多久,节点会不会宕机)。Agent们拿着这份“未来剧本”再做决策,从“被动反应”升级为“主动预判”。
-
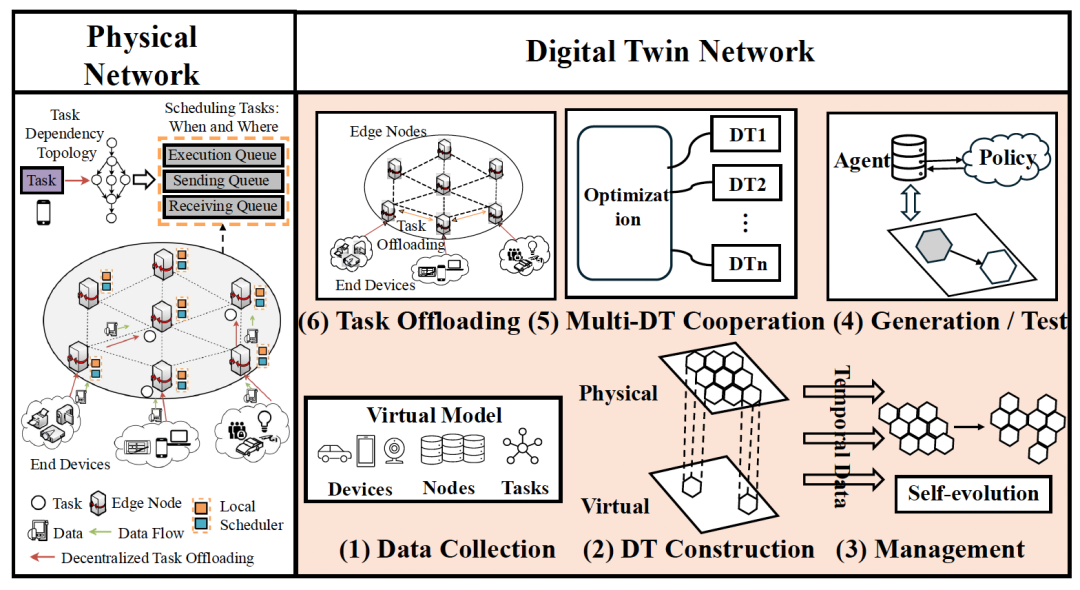
分层数字孪生架构图。它展示了 工作流程: (1) 从 “Physical Network” (物理网络)收集数据。 (2) 构建 “Virtual Model” (虚拟模型)。 (3) 在 “Management” (管理)阶段, Agent 与 Policy (策略)交互, DTs 之间也进行 “Multi-DT Cooperation” (多 DT 协作)。 (4) 生成 / 测试。 (5) 协作。 (6) 最终执行 “Task Offloading” (任务卸载)。
Agent如何实现“未卜先知”?
1. Agent架构剖析:前瞻性的“增强状态”
传统的Agent是“反应式”的(看到拥堵了才绕路)。但DT-MARL的Agent是“前瞻性”的。
它是如何实现的呢?
论文的精髓在于,它重新定义了Agent的“状态空间”。在任意时刻 ,Agent的决策依据 不仅仅是当前状态 ,而是被“增强”为:
- • :智能体 在 时刻的 当前观测 (如本地任务队列、可用算力)。
- • :数字孪生(DT)在 时刻预测出的 时刻的未来状态 (如预测的带宽、预测的节点故障率)。
这就好像你开车时,你不仅在看眼前的路况(当前状态),还在看导航系统预测的“10分钟后的路况”(未来状态)。你的决策自然更优!
2. 关键机制揭秘:DT-MARL的工作流
这套系统是如何运转的?
- 1. 问题建模: 整个系统被建模为一个“网络化分布式部分可观马尔可夫决策过程”(ND-POMDP)。这是MARL领域的“行话”,意思就是:一群Agent,视野(信息)有限,需要合作解决一个全局问题。
- 2. 智能体(Agent): 每个边缘节点都是一个Agent。
- 3. 混合动作空间: Agent的动作是“混合”的,非常符合现实:
- • 离散动作: 决定把这个子任务交给 谁 (节点A、B还是C?)。
- • 连续动作: 如果交给B,我该给这个任务分配 多少 带宽?
- 4. 奖励机制(Shapley Q-value): 目标是最大化全局的“任务成功率”。为了公平地给每个Agent“发工资”(分配奖励),论文用了一种“沙普利值”(Shapley Value)的思想,来估算每个Agent对“集体胜利”的边际贡献。
- 5. 训练范式(CTDE):
- • 集中式训练(CT): 在“训练营”(模拟器)里,所有Agent可以共享信息,在DT的帮助下高效学习策略。
- • 去中心化执行(DE): 到了“真实战场”,每个Agent就只看自己的本地信息和DT的预测,独立、快速地作出决策。
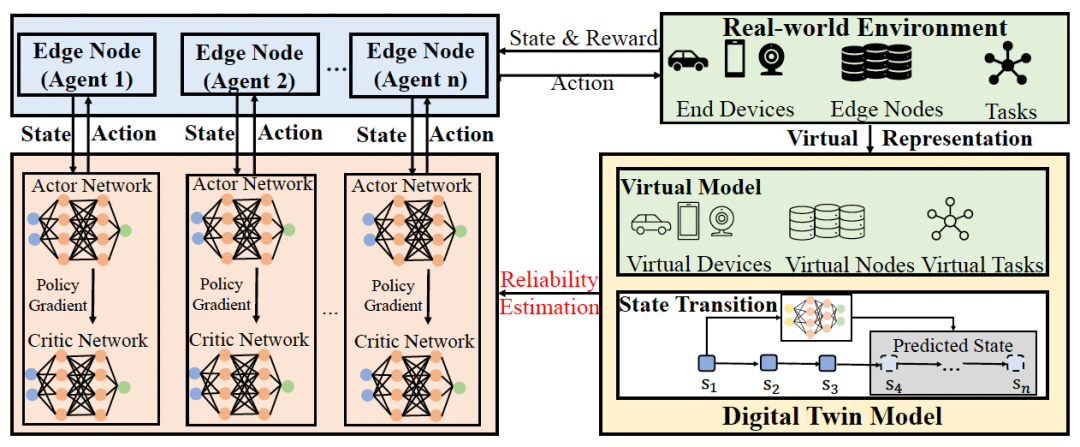
这就是 DT-MARL 的 “ 集中式训练 ” 框架图。左侧是多个 Agent ( Edge Node 1…n ),每个 Agent 都有自己的 Actor Network (演员网络)和 Critic Network (评论家网络)。它们与 “Real-world Environment” (真实环境)交互,产生 “State & Reward” (状态和奖励)。同时,右侧的 “Digital Twin Model” (数字孪生模型)提供了 “Virtual Representation” (虚拟表示),帮助 Agent 进行 “Reliability Estimation” (可靠性估计)和预测 “Predicted State” (预测状态)。
实验验证:效果究竟如何?
“是骡子是马,拉出来遛遛。” 论文的实验设计非常扎实,用了“真实世界”(阿里巴巴数据集)和“模拟世界”(随机DAG生成)两套数据。
核心指标: 任务成功率(TSR)。
对照组(基线):
- • LE(本地执行): 打死不卸载,累死自己。
- • RATC: 一种简单的启发式算法。
- • MARL-NTD(无任务依赖): MARL,但无视任务A必须在B之前的规则。
- • MARL-NBW(无带宽分配): MARL,但只管分配任务,不管路(带宽)堵不堵。
- • MARL-NTR(无可靠性): MARL,但不考虑节点会挂掉。
实验结果与分析
1. DT-MARL 完胜!
在所有场景下(不同任务量、不同带宽、不同节点数),DT-MARL都“吊打”了所有基线。在真实数据集上,任务成功率最高时比“本地执行”(LE)提升了 32.00% ,在合成数据集上提升了 32.43% !
2. 消融实验的意义
那些MARL-NTD、NBW、NTR(即“残血版”MARL)的表现都远远不如DT-MARL。这完美证明了:同时考虑 任务依赖、带宽分配、可靠性 这三件事,缺一不可!而DT-MARL是唯一一个把这三者都“管起来”的去中心化方法。
3. 泛化能力
作者还做了泛化实验。模型在(10个节点,25个设备)上训练,然后直接拿到(50-100个设备)的 全新未知环境
中测试。结果显示,TSR虽然有所下降,但依然保持了可接受的性能,证明了DT-MARL具有不错的泛化能力。
4. 系统开销
很多人会担心“数字孪生”这么高级,是不是很慢?实验证明,即使在100个节点的网络中,DT-MARL的决策开销(包括DT预测)也 低于0.2秒
,完全可以用于实时决策。
洞察与展望
1. 论文亮点与贡献
这篇论文最大的亮点,是把数字孪生(DT)从一个“监测”工具,升级为了一个“决策赋能”工具。它不再是MARL的“附属品”,而是成为了 Agent的“外置大脑”和“未来探测器” 。
通过将DT的“预测能力”融入Agent的“状态空间”,它完美地解决了MARN的三大“原罪”:探索风险高、样本效率低、被动决策。
2. 潜在应用场景
这套“DT-MARL”框架的应用场景非常广。任何需要 高可靠、低延迟、去中心化协作 的场景,都大有可为:
- • 自动驾驶车队: 车辆(Agent)之间协同决策,DT预测其他车辆的意图和路况。
- • 工业物联网(IIoT): 产线上的机器(Agent)协同,DT预测设备故障和物流瓶颈。
- • 智慧城市/视频分析: 摄像头和边缘服务器(Agent)协同,DT预测人流和计算负载。
- • 具身智能: 一群机器人(Agent)在未知环境中协作,DT模拟物理交互,预测行动后果。
3. 局限性与未来研究方向
作者也坦承,目前的模型虽然对 负载 (用户增多)有一定的泛化能力,但如果网络 拓扑结构 (比如节点连接方式)大改,还是需要重新训练。
这指向了未来的研究方向:开发更具普适性的“世界模型”(World Models),让Agent在完全陌生的网络环境中也能快速适应,真正实现“即插即用”的智能协作。
你认为数字孪生和Agent的结合还有哪些“神仙”玩法?欢迎在评论区留下你的思考!如果你觉得今天的分享有所收获,别忘了 点赞、在看、转发 三连,一起探索AI Agent的无限可能!