DeepSeek V3 2万字报告解读

DeepSeek-V3.2 | 万字报告解读
刚刚,DeepSeek团队悄无声息地丢出了一枚“核弹”—— DeepSeek-V3.2 。

如果说之前的模型是在“教AI做题”,那么V3.2就是在“教AI干活”。我们知道,开源模型虽然在追赶闭源巨头(如OpenAI、Anthropic),但在 复杂Agent(智能体)任务 、 长上下文处理效率 以及 指令遵循 上,始终存在一道“看不见的墙”。
今天分享的这篇技术报告《DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models》,正是为了打破这道墙而来。它不仅在推理能力上硬刚GPT-5(High),更重要的是,它提出了一套让Agent“既聪明又省钱”的全新方案。
准备好了吗?咱们一起潜入这篇硬核论文,看看DeepSeek又是如何重新定义“开源最强”的!
2. 概览与核心贡献
2.1 DeepSeek-V3.2 是做什么的?
简单来说,DeepSeek-V3.2 是一个 追求极致性价比与极致智力 的开源模型。
它没有单纯地堆砌参数,而是通过架构创新和数据合成,解决了两个核心痛点:
- 1. 长窗口太贵太慢 :传统的注意力机制处理长文档时计算量爆炸。
- 2. Agent不够聪明 :开源模型在调用工具和复杂规划时,往往不如闭源模型灵活。
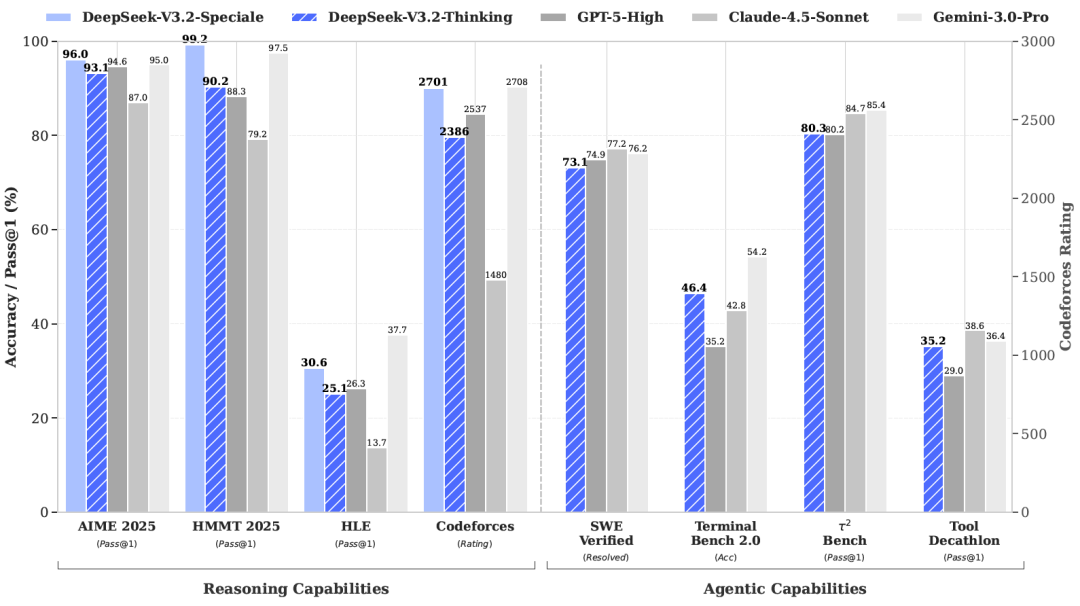
图片描述 :DeepSeek-V3.2 与 GPT-5-High、Gemini-3.0-Pro 等顶级模型在 AIME、Codeforces 等基准上的性能对比柱状图。这张图直观展示了 V3.2 在多项指标上逼近甚至超越闭源模型的强悍实力。
2.2 核心思想与“杀手锏”
这篇论文的“杀手锏”主要有三招:
- • DeepSeek稀疏注意力 (DSA) :这是一种全新的注意力机制。如果说传统模型是在“通读全书”找答案,DSA就像是拥有一个“闪电索引”,只挑最关键的页面读,极大地降低了计算复杂度。
- • 可扩展的强化学习 (RL) :他们把DeepSeek-R1的“思考(Thinking)”能力完美移植到了Agent任务中,并通过大规模的后训练(Post-training),让模型在工具使用中也能进行深度推理。
- • 大规模Agent任务合成 :为了解决Agent训练数据不足的问题,DeepSeek自研了一套流水线,凭空生成了数百万高质量的Agent任务数据。
3. 核心技术深度解析
3.1 架构剖析:DSA与闪电索引
在DeepSeek-V3.2中,架构的最大亮点就是 DSA (DeepSeek Sparse Attention) 。
痛点 :传统的Transformer使用的是“全注意力”,随着输入内容变长(比如128K tokens),计算量呈平方级增长。这对显存和速度都是灾难。
DSA的魔法 :
DSA引入了一个“闪电索引器(Lightning Indexer)”。
- • 比喻时刻 :想象你在图书馆找资料。传统模型是把图书馆里每一本书都翻一遍(全关注)。而DSA是先看“索引目录”(索引器),快速筛选出最可能包含答案的几本书(Top-k),然后只精读这几本书。
- • 结果 :计算复杂度从平方级降到了线性级,在保持长上下文性能的同时,推理成本大幅下降。
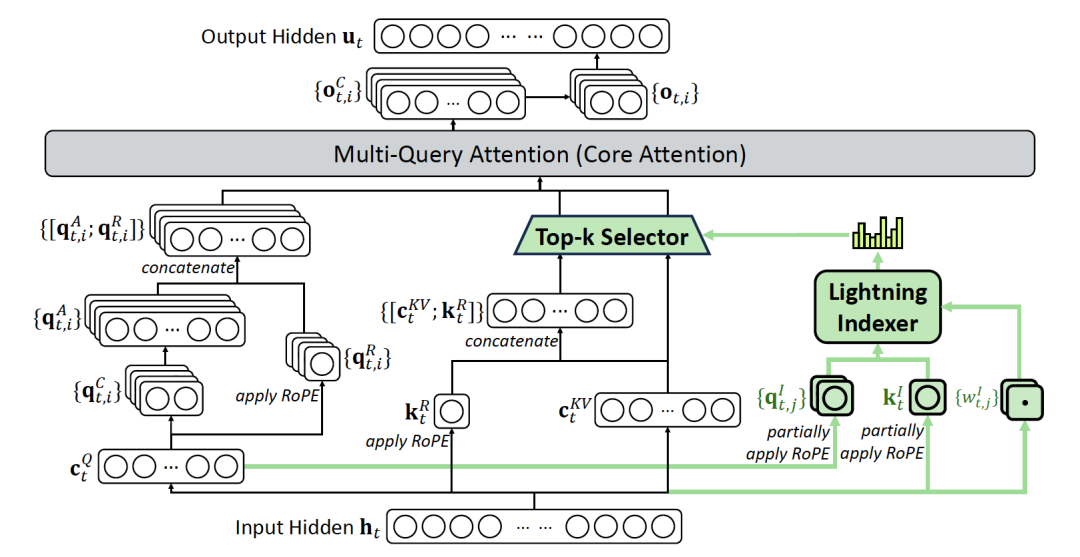
图片描述 :DeepSeek-V3.2 的注意力架构图,详细展示了 DSA 如何通过 Lightning Indexer 和 Top-k Selector 实现稀疏注意力选择。
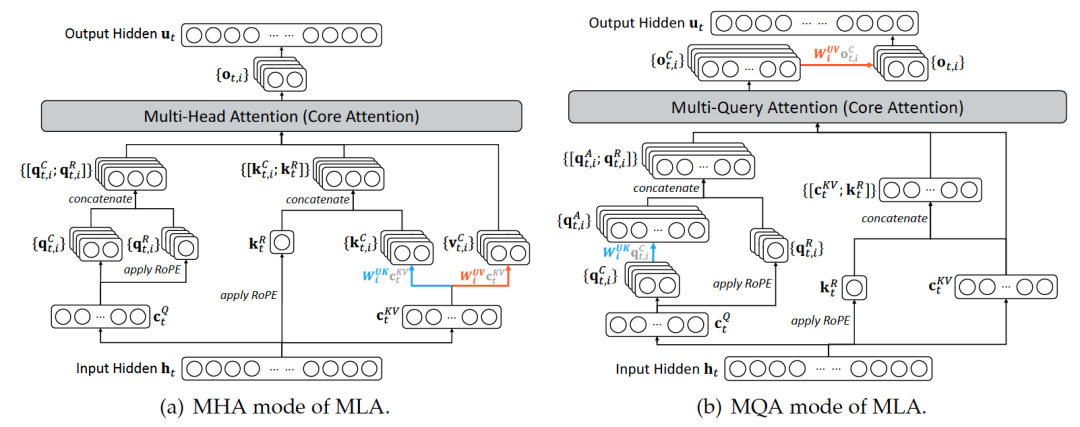
图片描述 :(可选插入,作为技术补充) MLA 的 MHA(训练模式)与 MQA(推理模式)示意图,展示了其底层的高效注意力实现细节。
3.2 Agent思维:思考与工具的融合
这是我们“AI智使”最关注的部分。DeepSeek-V3.2 是如何让Agent变聪明的?
1. 工具使用中的“思考” (Thinking in Tool-Use)
以前的Agent,要么只会思考(CoT),要么只会调工具。V3.2将两者结合,让模型在调用工具前先进行一段“思维链”推理。
- • 上下文管理难题 :如果保留所有的思考过程,上下文很快就会爆满;如果删掉,模型又会“失忆”。
- • 解决方案 :DeepSeek设计了一种精妙的 上下文保留机制 。当用户输入新指令时才清除旧的思考,但在多轮工具调用中,保留当前的推理痕迹。这就像人工作时,做完一个大项目(User Message)才清空草稿纸,而在项目进行中(Tool Calls)草稿纸一直保留。
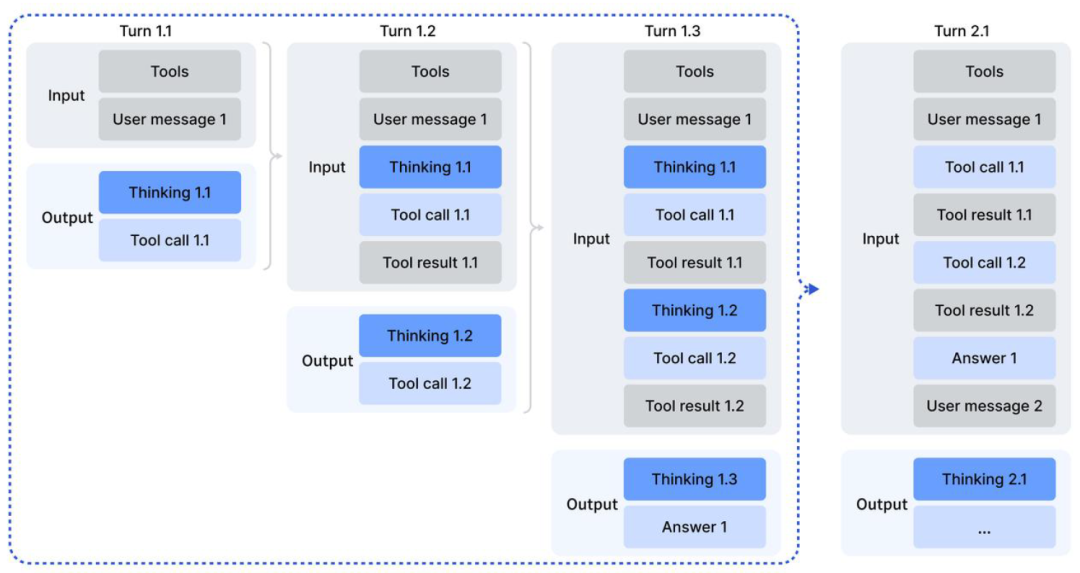
图片描述 :工具调用场景下的思维保留机制流程图。清晰地展示了在 Turn 1.1 到 Turn 2.1 的过程中,Thinking 内容何时被保留,何时被丢弃。
此外,针对搜索等长轨迹任务,DeepSeek还测试了不同的上下文管理策略(如丢弃历史、总结历史),以平衡性能与Token消耗。
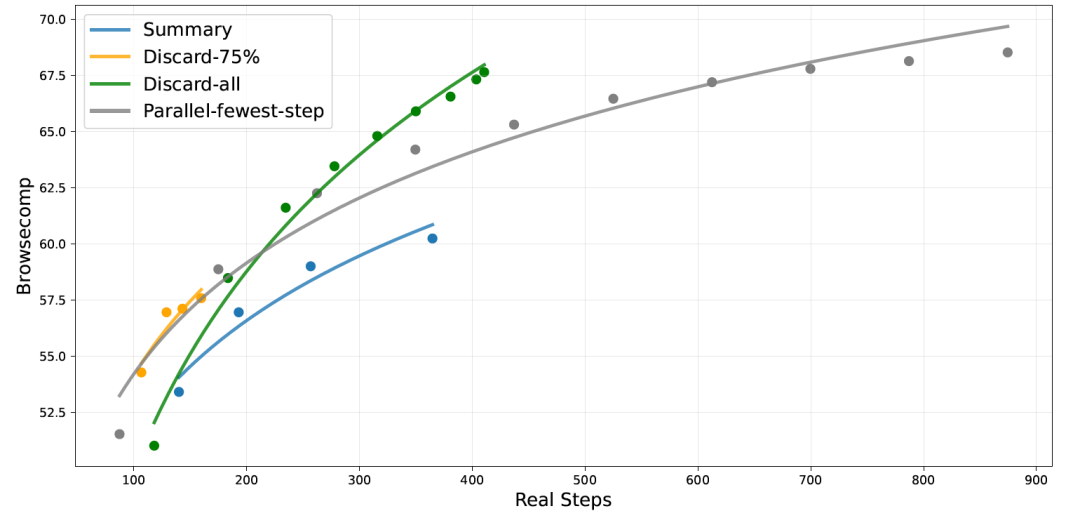
图片描述 :在 BrowseComp 基准测试中,不同测试时计算扩展策略(如 Summary, Discard-75%)的准确率随步骤数变化的曲线。
2. 大规模Agent任务合成流水线
数据是AI的燃料。为了训练强大的Agent,DeepSeek构建了一个自动化工厂:
- • Search Agent :利用多智能体在互联网上挖掘长尾知识,生成问答对。
- • Code Agent :从GitHub挖掘数百万个Issue和PR,构建可执行的修复环境。
- • General Agent :这是最酷的!通过“环境合成Agent”,凭空创造了1800多个虚拟环境(比如模拟一个订票系统或操作系统),并生成与之交互的任务。这就像是给AI造了一个“元宇宙”训练场,让它在里面日夜不停地打怪升级。
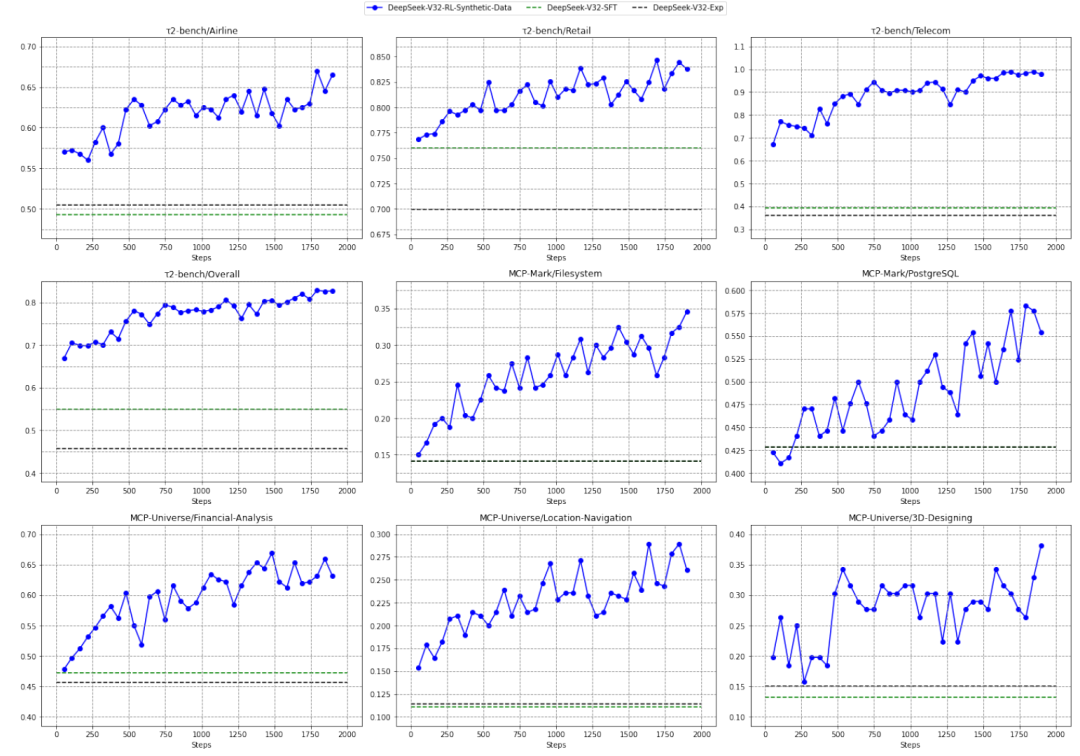
图片描述 :DeepSeek-V3.2-SFT 仅使用合成的通用 Agent 数据进行 RL 训练后的性能提升曲线。可以看到随着训练步数增加,Pass@K 准确率稳步上升,证明了合成数据的有效性。
4. 实验验证:效果究竟如何?
4.1 实验高光时刻
DeepSeek团队在多个硬核基准上测试了V3.2,包括代码(SWE-bench)、数学(AIME)、以及工具使用(Tool-Decathlon)。
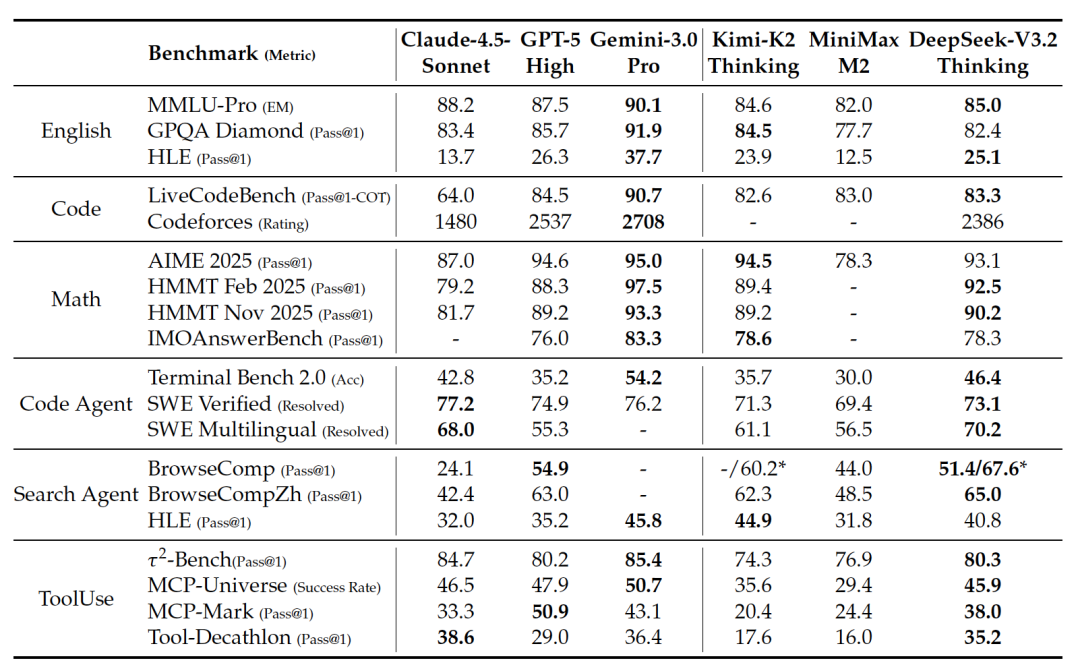
图片描述 :DeepSeek-V3.2 与 Claude-4.5-Sonnet、GPT-5-High 等模型在各项基准(English, Code, Math, Agent)上的详细跑分对比表。
主要战绩 :
- • DeepSeek-V3.2-Speciale(高算力版) :这是为了探究极限性能的版本。它在 2025国际数学奥林匹克 (IMO) 和 信息学奥赛 (IOI) 中均获得了 金牌级 的表现!在推理能力上,它超越了 GPT-5-High,与 Google 的 Gemini-3.0-Pro 持平。
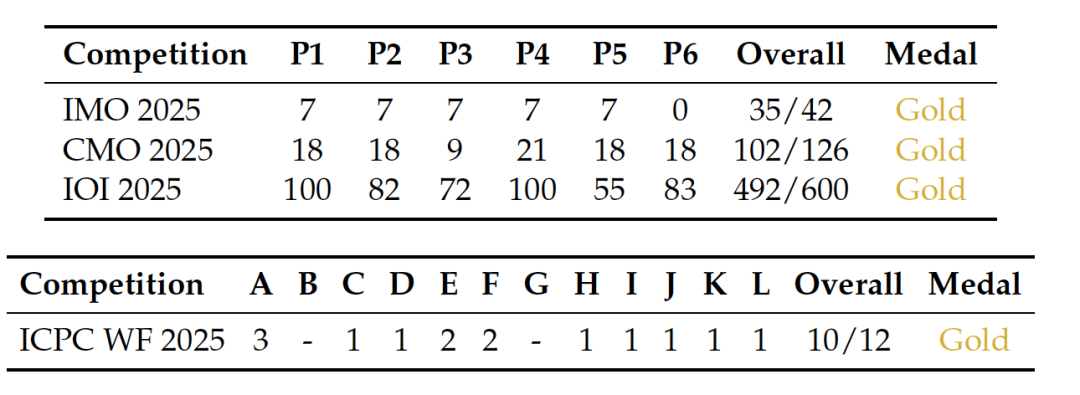
图片描述 :DeepSeek-V3.2-Speciale 在顶级数学和编程竞赛(IMO, IOI, ICPC WF)中获得金牌表现的详细得分统计。
- • 标准版 V3.2 :在保持极高性价比的同时,其Agent能力在 SWE-Verified(代码修复)和 Terminal Bench(终端操作)上显著优于其他开源模型,甚至逼近闭源前沿。
4.2 成本与效率
得益于DSA架构,V3.2的长文本推理成本大幅降低。图表显示,随着上下文长度增加,V3.2的成本增长曲线远比上一代平缓。这意味着,我们可以用更少的钱,跑更复杂的Agent任务。
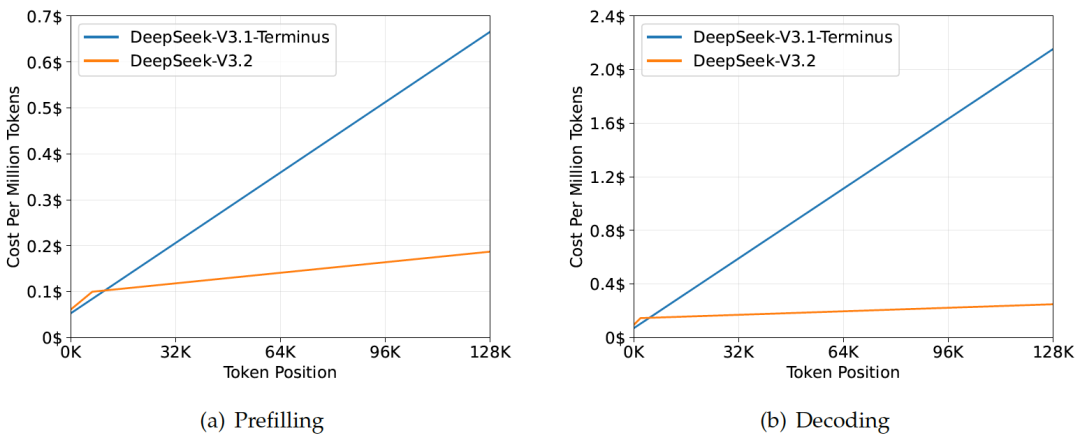
图片描述 :DeepSeek-V3.1-Terminus 与 DeepSeek-V3.2 在不同 Token 位置的推理成本对比图(包含 Prefilling 和 Decoding 两个阶段)。
5. 亮点与局限
5.1 论文亮点与贡献
这篇论文最大的贡献在于证明了: ** 开源模型不需要单纯依赖堆算力,也能通过架构优化(DSA)和高质量合成数据(Agent Synthesis)来挑战闭源巨头。 **
特别是它展示的“思考型Agent”路径:让模型在按按钮(调用工具)之前,先在脑子里转几圈(Thinking Process)。这极大地提升了Agent处理复杂、多步骤任务的成功率。
5.2 潜在应用场景
- • 全自动编程助手 :鉴于其在SWE-bench上的优异表现,V3.2非常适合集成到IDE中,处理真实的代码库Issue。
- • 长文档智能分析 :DSA架构让它能低成本处理几十万字的法律合同或金融财报,提取关键信息并进行逻辑推理。
- • 复杂任务规划 :比如“帮我策划一次跨越三个国家的旅行,要最省钱且不走回头路”,V3.2的通用Agent能力将大放异彩。
5.3 局限性与未来
当然,DeepSeek也坦诚地指出了不足:
- 1. 世界知识储备 :由于预训练计算量仍少于万亿级参数的闭源模型,V3.2在某些冷门知识上可能不如Gemini-3.0。
- 2. 啰嗦 :为了达到高准确率,模型往往需要生成很长的“思考过程”,这虽然提高了质量,但也增加了等待时间和Token消耗。
未来,如何提高“思维密度”,让模型想得少一点但想得对一点,是研究的新方向。
6. 总结
DeepSeek-V3.2 的发布,无疑给开源社区打了一针强心剂。它告诉我们,Agent的未来不仅仅属于那些拥有数万张H100的巨头,精妙的算法设计和数据工程同样能创造奇迹。
作为AI Agent的探索者,我们正处于一个激动人心的时代。DeepSeek已经把路铺好了(代码和权重均已开源),接下来就看我们如何用它去创造价值了!
互动时间 :
读完这篇硬核解读,你认为 “稀疏注意力” 会成为未来大模型的标配吗?你最想用 DeepSeek-V3.2 构建什么样的 Agent?
欢迎在评论区留下你的脑洞!如果你觉得今天的分享对你有帮助, 请点赞、在看、转发三连 ,让更多智使加入我们,一起见证AI Agent的进化之路!
关注【AI智使】,获取最前沿、最硬核的AI Agent资讯与教程。
以上就是今天分享的全部内容。如果觉得有所收获,记得一键三连,点个 关注、分享、喜欢 , 也 欢迎将文章分享给更多有需要的同学 。
我创建了一个高质量的 「论文研读社群」,专注于大模型、AI Agent等方向。在这里,我们 每日打卡 (精读并分享最新的Agent动态和顶会论文), 定期讨论 (围绕关键技术与研究思路进行深入交流), 资源共享 (共享高质量的学习资料与科研工具)。后台私信添加WX1947099691或下方扫码” Agent ”拉你入群。
